Building Vs Buying a PIM: Managing Products (Part 2)
A product information manager (PIM) is primarily responsible for storing product data, allowing team members and partners to create and update that data, and distributing product data to customers. In part one of this series, I walked you through setting up your PIM’s data model, and in this post, I’ll walk you through the technical challenges you will need to solve surrounding collecting, importing, and modifying data within your PIM.
While you have to get the core data model right, a useful PIM needs to be dynamic, allowing team members, partners, and engineers to modify products quickly and easily. In this post, you’ll see how to make sure your PIM can be used by internal stakeholders, third-party partners, and engineers who want to run bulk import scripts.
- Building Vs Buying a PIM: Product Data and Variations (Part 1)
- Building Vs Buying a PIM: Managing Products (Part 2)
- Building Vs Buying a PIM: Product Data Distribution (Part 3)
Why Product Data Gets Modified
For context, it’s important to understand why product data in your PIM will need to be changed. In a small e-commerce company, it might be trivial to upload a few products to your database or write a script to import them and then move on to more interesting problems. But, what happens when you notice a typo in a product description? Or you decide to launch a new product? Or release a new variation? You don’t want to have to devote engineering time to every little product change that comes up.
In the context of a large e-commerce company with hundreds or thousands of SKUs, this problem becomes even more intractable. I once worked at a textbook sale and rental company with over 100,000 books in our database, and I can tell you that we couldn’t have kept up with the flood of manual update requests for long.
The solution to this problem is to build an internal interface that allows users to update and create data stored in your PIM. These interfaces can come in two forms: a user interface that your product or operations teams can access or a machine interface that your engineering or data teams can use to modify data programmatically.
In the following sections, I’ll review the primary technical considerations engineers will need to make when building the data-ingestion portion of a PIM. I’ll also show you how integrating with Fabric’s PIM can save you time and money by offering a ready-made headless e-commerce backend for your business.
Building a Product Management System for Your PIM
Most large e-commerce companies have a team (or several teams) responsible for keeping product descriptions, images, variations, and specifications up to date. This team will likely be the primary user of your internal PIM interface, but you might also open up access to some vendors or partners.
Depending on their use cases, these teams will either use a user interface or API to manage data stored in your PIM. Some use cases include checking products before they go live, creating new products, fixing errors, changing product specifications, and uploading images, videos, or PDF manuals. There are a number of technical considerations software engineers should weigh when building the data management side of their PIM.
User Interface Design
It’s tempting to cut corners when designing a user interface for your PIM because it’s not likely to be a customer-facing feature, but this is a mistake.
“There’s a myth that spending a lot of time researching and designing internal products isn’t as important as customer-facing products…But what normally happens is an accumulation of quick wins on top of each other until you finally end up with a ‘Frankenstein tool’ that looks more like an agglomeration of buttons rather than something actually usable.” – Nicolo Arena, Product Designer at TransferWise
The less intuitive and more error-prone your user interface is, the more support requests will bog down your engineering team as a result. Treat your PIM’s UI with as much respect as a customer-facing one: do user research, test different designs, and iterate on them over time.
The hard thing about building a robust PIM interface is that products aren’t just static spec sheets. You’ll need to handle variations, categories, groups, and taxonomies, as well as descriptions, file uploads, and product names.
Teams that use Fabric’s PIM get a web-based user interface as part of the platform. This allows marketers, merchandisers, and other business users to create and edit products, product families, categories, collections, and much more without requiring the engineering team’s assistance.
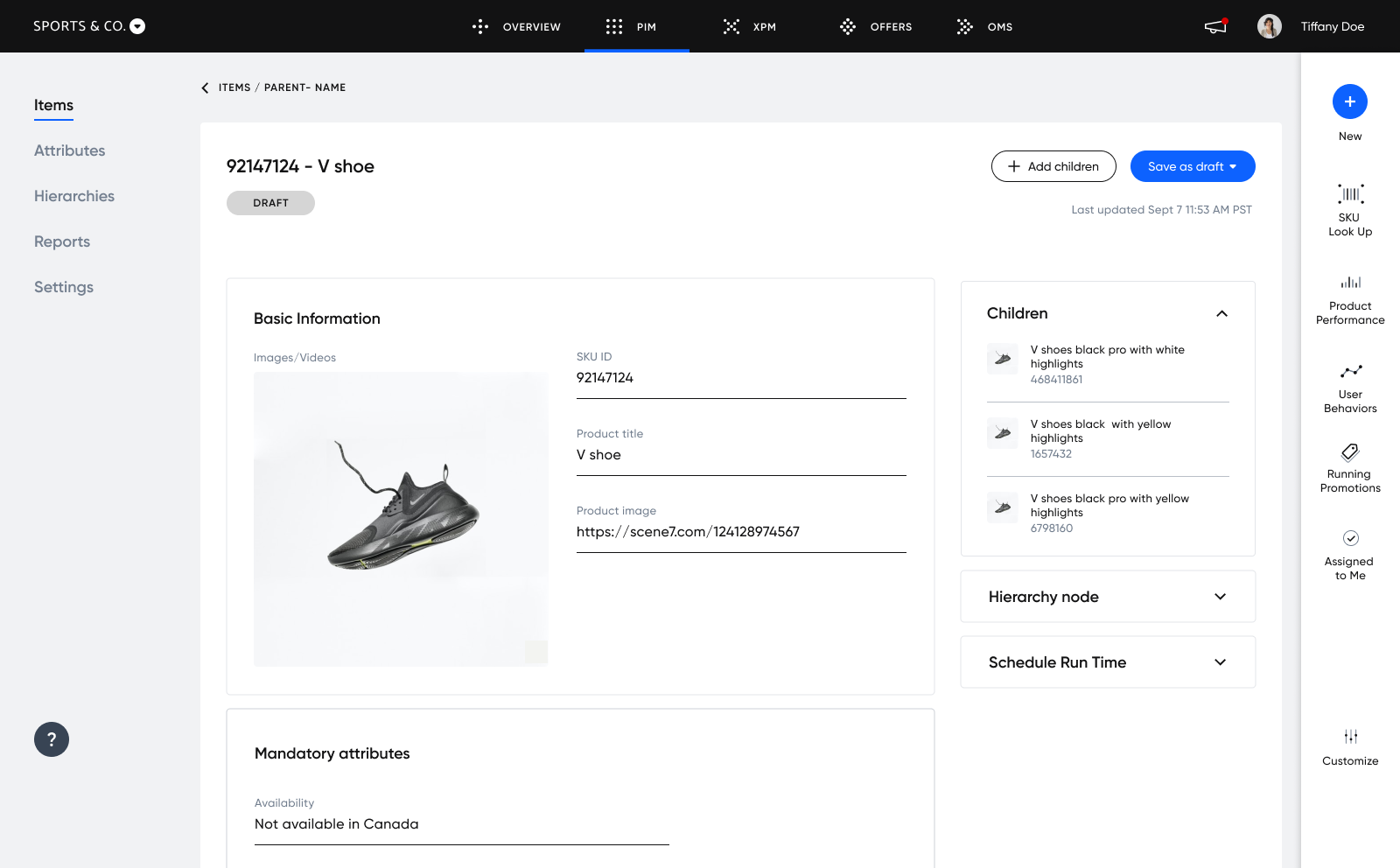
Data Validation
A key part of any PIM is data validation. You’ll need to consider how your PIM handles mistakes like trying to create two products with the same SKU, missing names or descriptions, or improperly-sized images. There’s a backend component to this (should the bad data be stored or simply thrown out?), and then there’s a frontend component as well (how should we tell users about the issue?).
While some modern web frameworks include form validation rules that make this easier, data validation is always more complicated than it looks. Your frontend, API layer, and database all need validation rules, and you have to be careful to avoid conflicts between them.
Some PIM software lets you set validation rules that help guide users as they create products in your database. For instance, when creating new attributes, you can set the attribute as mandatory to ensure that certain products have consistent attributes and product data.
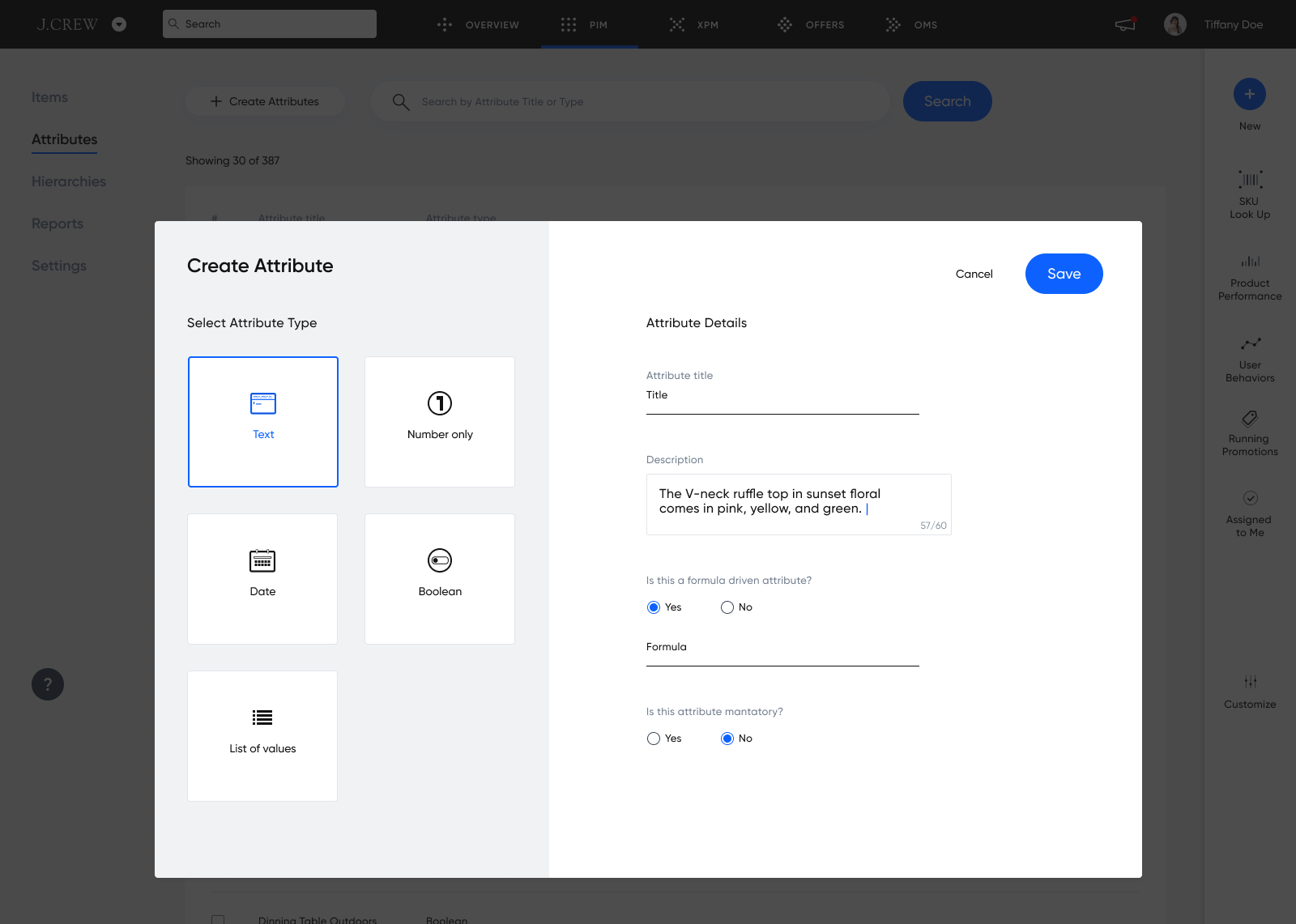
Search
While most e-commerce teams think about product search from a customer perspective, this isn’t necessarily the same as building an internal search tool for your PIM’s UI.
For example, your internal team might need to search by product SKU, manufacturer, or whether the product has a specific data point (i.e., find all products without an image so you can update them). Search is notoriously hard to build well, and is often underestimated in engineering projects:
“Not appreciating or understanding the scope and complexity of search problems can lead to bad user experiences, wasted engineering effort, and product failure.” – Max Grigorev, Chief Science Officer at Wilbur Labs
Bottom line: your PIM should give you the ability to search and filter your products based on their attributes, categories, families, and more. This makes it very easy for your team to find and modify products quickly to keep them up-to-date for customers.
Permissions and Security
Even if you limit access to your PIM to internal team members, you still need to ensure that users have adequate permission to modify specific products. If you open your PIM up to third-party vendors or manufacturers, security becomes an even bigger concern.
Building user authentication and authorization into your PIM is the obvious first step, but there are other important considerations as well. Do you need to allow users to invite other users, or can anyone create an account? Are some teams responsible for certain products and other teams for others? Will vendors only be able to access certain fields?
If you add API support to your PIM, you will need to implement OAuth, basic auth, or API keys as well. Without a secure method of access control, you open yourself up to attackers who might alter data in your PIM.
As the complexity of your security model increases, your development time and risk surface area will increase. Keeping it simple while preventing malicious or unauthorized access is key to building a robust PIM.
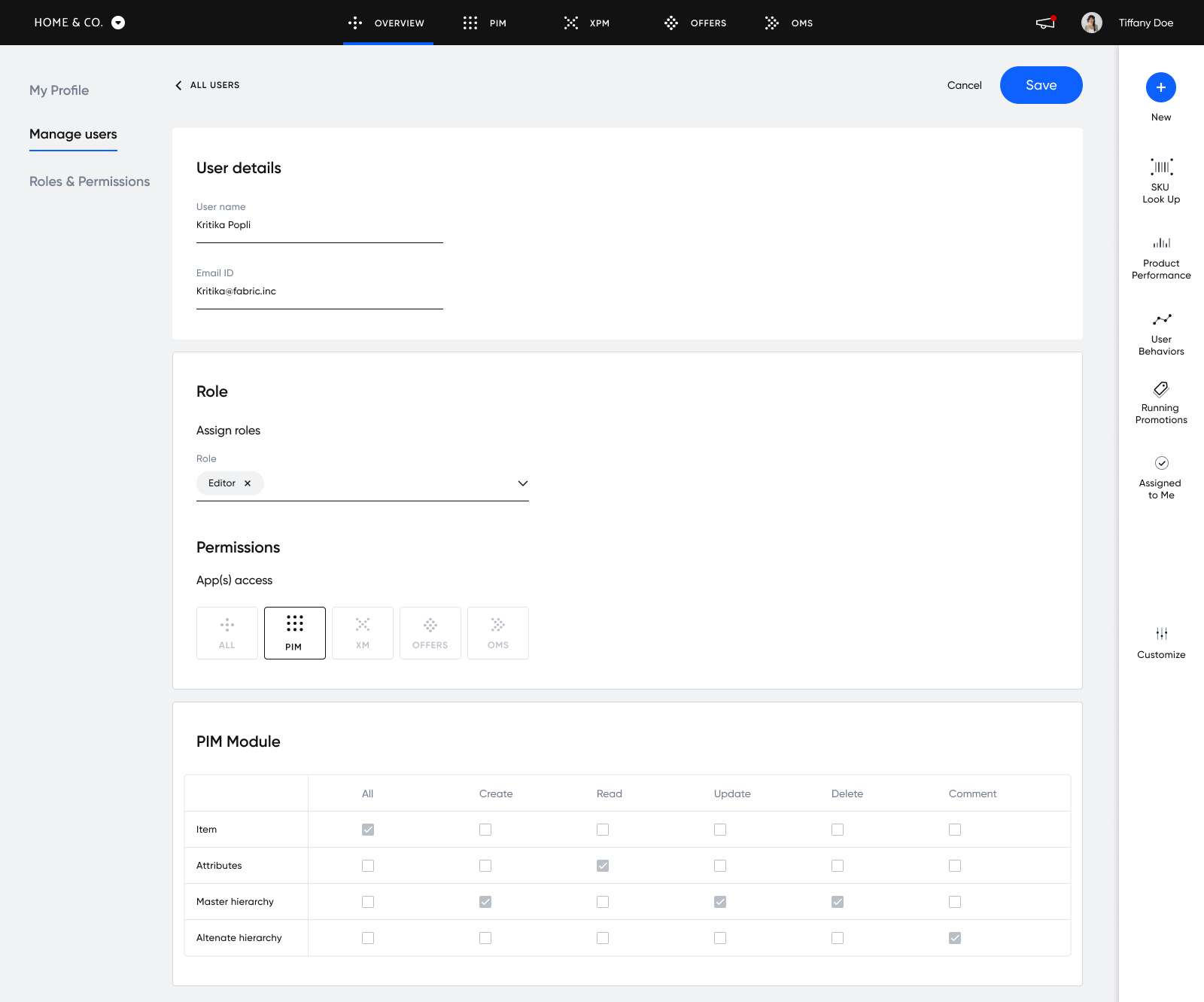
Below is an example of how admins can manage users, roles, and permissions inside Fabric’s user interface. Admins can give users access to all apps or select apps like PIM and limit permissions (Create, Read, Update, Delete, Comment) to certain parts of the app (Item, Attributes, Master hierarchy, Alternate hierarchy).
Bulk Uploads
Most e-commerce companies with large product catalogs need to support some kind of bulk import process using Excel or CSV files. While bulk imports save end-users a lot of time, they also introduce a lot of complexity for software engineers.
You have to build an endpoint that can handle large files, queue up a batch of imports, check each row for formatting or structural errors, parse each row, handle each imported product, deal with failed imports, and notify users when the process is complete. Having built bulk import tools several times in the past, I can tell you, it’s impossible to imagine all the ways users will mess up the formatting of a spreadsheet.
One way to avoid this challenge is to set up a bulk upload feature inside the user interface that includes a CSV template. This template makes it much harder to mess up the formatting on your imports.
API Documentation
Your PIM’s user interface is important, but for teams that manage thousands of products, you likely need to support an API-based interface as well. This will allow your engineering or data teams to programmatically update product specs from partners or vendors. You might also use the API to allow external users to create products if you run a marketplace or are a reseller.
For APIs, documentation is essentially the user interface, so while using commonly accepted standards can help, you still need detailed documentation. Fortunately, building good developer docs has gotten easier thanks to some great tools that are now available, but it still takes time.
If you want partners to easily integrate with your PIM’s API, you might also want to build an SDK that supports common programming languages. Maintaining good docs and SDKs is a full-time, but important part of building a robust PIM.
Scalability
While scalability matters in all aspects of designing a PIM, data ingestion has some unique considerations. For example, what will your system do when a user tries to import 10,000 products at once? Or when they upload 1000 images in a minute? Whether large payloads hit your API or user interface, you need to consider how your PIM will handle them.
First, if your PIM supports API-based access, you should implement rate limiting and payload size restrictions to prevent users from intentionally (or accidentally) DDOSing your service.
“Because they’re often available over public networks, APIs are typically well documented or easily reverse-engineered. Also highly sensitive to denial of service (DDOS) type incidents, APIs are attractive targets for bad actors.”- Francois Lascelles, Field CTO at Ping Identity
You should also implement queues to break up long-running jobs and process them one at a time, and set up autoscaling to dynamically increase your compute power as needed. These scaling methods introduce other challenges though. For example, it’s harder to trace failures and logs when your system is built on asynchronous queues.
In my experience, scaling is one of the most challenging parts of building a successful software product. The work never really ends, which brings me to the last consideration you should make when building the data management portion of your PIM: maintenance.
Maintenance
Up to 90% of the total cost of building software is made up of maintenance costs. Product managers starting a new project rarely consider the impact that ongoing support will have on the business, so even if you are ready to take on the cost of building a PIM in-house, make sure you can allocate enough engineering time to fix bugs and add new features over time.
One of the most compelling arguments for using third-party PIM SaaS is that you won’t have to support ongoing feature requests and maintenance. If your engineering team is already stretched thin with your existing product, keep this tradeoff in mind as you weigh the pros and cons of building a PIM.
Conclusion
Building a PIM in-house will give you control and flexibility over your product management interface, but you’ll have to keep in mind the cost of building and maintaining that software. Using a third-party PIM can save you both the up-front cost of developing the product and the long-term cost of keeping it running. It can also handle security, scaling, and other tricky parts of the PIM engineering work for you.
In the last post in this series, we’ll talk about how your PIM will expose your product data to the world. This will give you a complete idea of the engineering challenges inherent in building a PIM that enables you to grow your e-commerce business and reach users on any platform.

Tech advocate and writer @ fabric. Previously CTO @ Graide Network.
Related Content